C++ Unordered Map Under the Hood
The std::unordered_map in C++ standard library is a really powerful data structure offering insertion, deletion, and lookup in O(1) amortized time. std::unordered_map is implemented as a hashmap or hashtable which are the same thing. This article is going to describe how the C++ standard library implements the unordered_map, how it achieves those time complexities, and when to use it.
Member Variables
class unordered_map{
private:
list<pair<int,int>> *buckets;
int bucket_size;
int total_elements;
float max_load_factor;
}std::unordered_map is an array of linked lists of pairs. They’re pairs because they store a key value pair which are both integers in our case. bucket_size is the size of the array. total_elements is the current number of key value pairs. The max_load_factor is the max ratio of total_elements to bucket_size. If it exceeds this, the hash table is rehashed. Below is a picture representing buckets
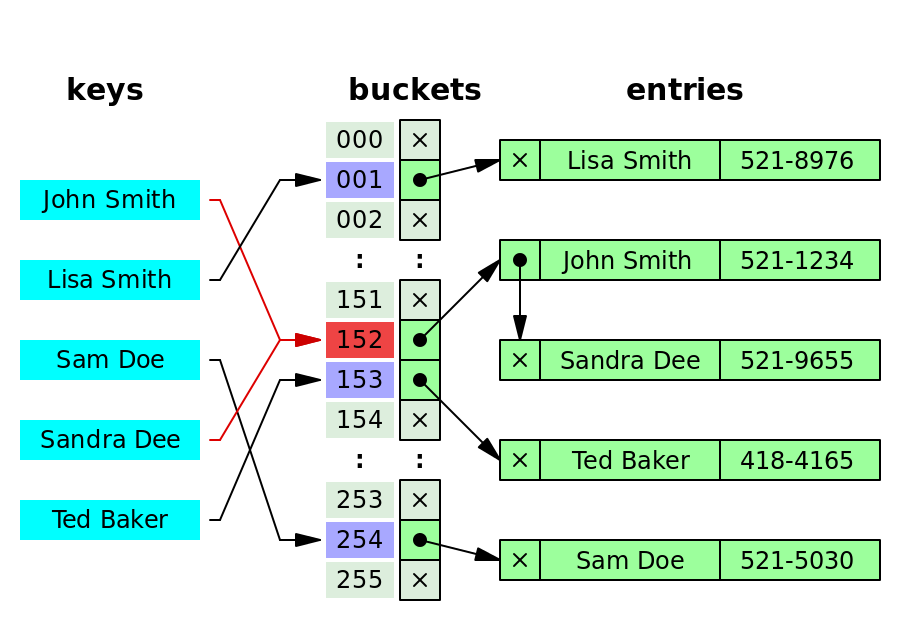
Keys are hashed to an index in the array, aka a bucket. In each bucket is the head of a linked list. For example, John Smith and Lisa Smith happen to hash to the same bucket, 152. Thus, they both get added to the linked list for bucket 152. When keys map to the same bucket, this is called a collision.
Functions
int hash(int key) {
int hashed_key = strongHashingFunction(key)
return hashed_key % bucket_size;
}hash takes in a key, uses a strong hash function, which could be custom, then mods it by the bucket_size to get the bucket index. It’s very important to use a good strongHashingFunction that can evenly and randomly distribute its outputs. If not, you will have more collisions which could degrade the time complexity significantly.
list<int>::iterator find(int key){
for(auto& i : buckets[hash(key)]) {
if(i->first == key){
return i;
}
}
return buckets[hashed_key].end();
}find will search for the key and return a list iterator to it if it exists.
void insert(int key, int val){
auto it = find(key);
if(it != buckets[hash(key)].end()){
it->second = val;
return;
}
buckets[hash(key)].push_back({key,val});
total_elements++;
rehashIfNeeded();
}insert first checks if the key exists already. If so, it modifies that key’s value. Otherwise, it pushes the value back on the linked list. If needed we’ll expand the buckets and rehash everything.
void delete(int key){
auto it = find(key)
if(it != buckets[hash(key)].end()){
buckets[hash(key)].erase(it);
total_elements--;
}
}delete finds the key by calling find. It will delete it if found
void rehashIfNeeded(){
if(total_elements/bucket_size <= max_load_factor){
return;
}
bucket_size *= 2;
auto new_buckets = new list<pair<int,int>>[bucket_size];
for(int i = 0; i < bucket_size/2; i++){
for(auto& kv_itr: buckets[i]){
new_buckets[hash(kv_itr->first)].push_back(*kv_itr);
}
}
delete[] buckets;
buckets = new_buckets;
}rehashIfNeeded first checks if the max_load_factor has been exceeded. If so, it will double the size of the array and rehash everything to the new one. The reason we rehash is to decrease the chance of collisions. max_load_factor is set to 1 by default in the standard library implementation. If the total_elements in the map is equal to the bucket_size then there is an average of 1 element per bucket, so collisions could happen but it’s unlikely a lot of them will happen on the same bucket. However, if you have a hashing function that’s time consuming or a lot of elements to copy over, you may want to consider giving the max_load_factor a bit more slack.
Complexity Analysis
find hashes in O(1), then traverses the bucket looking for the key. Assuming that we have a good low factor and a hash functions, the number of collisions or elements in this linked list is constant. In fact, on average, the number of elements in each bucket (collisions) should be less than the max_load_factor. Thus, find is O(1) on average.
delete calls find in O(1) and gets a list::iterator. lists are implemented as doubly linked lists in C++, and deleting a node in a doubly linked list is O(1) operation. Thus, delete is O(1) on average.
insert is a bit more tricky. Most of the time insert calls find in O(1) and does an O(1) modification to the pair, but every so often we have to rehash everything which is an O(n) operation where n is total_elements. So how do we measure a time complexity when its mostly O(1) and rarely O(n)? Do we just say O(n)? No, we used an amortized complexity.
Let’s say bucket_size=99 and max_load_factor=1. So, we insert 99 elements in O(1) time, then the 100th element in O(100) time, then our amortized time complexity is O(2) because (100 for rehashing + 1*every insert)=200 and we got 100 inserts completed. It’s kind of still an average according to the english definition, but it’s a different flavor of average. It’s like overtime, we know we’re going to hit this huge bump in time complexity, but it’s okay because the time complexity was low for so long before and things even out. Thus, insert is amortized O(1) on average.
Using an unordered_map
You should use an unordered_map when you don’t care about keeping a sorted order of the keys. I’d say, you’d use an unordered_map over an (ordered) map in C++ unless you have a reason for wanting to preserve order. map comes with a big complexity hit, so your usually better off with the unordered_map. For the full reference of std::unordered_map visit https://en.cppreference.com/w/cpp/container/unordered_map
